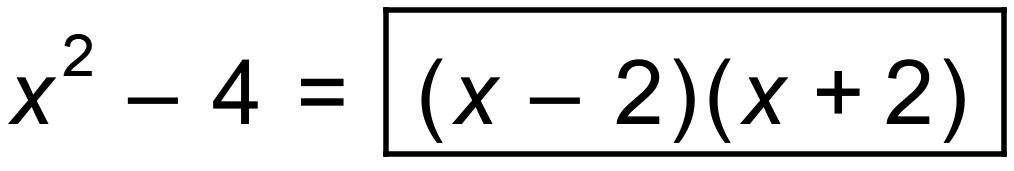We have implemented a new parameter and a number of new calculator commands that allow you to work with words. These allow you to implement probability questions like:
If you randomly select a letter from the word MISSISSIPPI, what is the probability that the letter you select will be a vowel.
You could implement this type of question using a LIST parameter.
$m=list(“M”,”I”,”S”,”S”,”I”,”S”,”S”,”I”,”P”,”P”,”I”)
but this quickly becomes onerous, especially if you want to include a range of words in your question.
New Explode Parameter.
The first change we have made is to implement a new Explode parameter.
$x=explode(“MISSISSIPPI”)
This takes the provided word and explodes it into a list – just like typing the extended list command above.
You can combine a list command and an explode command to create a question which deals with lots of different words.
$w=list(“MATHEMATICS”,”STATISTICS”,”ALGEBRA”,”TRIGONOMETRY”,”GEOMETRY”)
$x=explode($w)
This allows you to regenerate to randomly select a word and explode it into a list of letters.
New Calculator Commands
unique($x)
Creates a new list of the unique letters in a list of letters. If $x contains the exploded word MATHEMATICS, {unique($x)} will return the list
“M”,”A”,”T”,”H”,”E”,”I”,”C”,”S”
sort($x)
The sort command will sort a list of letters. If $x contains the exploded word MATHEMATICS, {sort($x)} will return the list”A”,”A”,”C”,”E”,”H”,”I”,”M”,”M”,”S”,”T”,”T”
You will often combine the sort and unique commands.
{sort(unique($x))} will return “A”,”C”,”E”,”H”,”I”,”M”,”S”,”T”
vowels($x)
This command returns a list of vowels in a word.
{vowels(sort(unique($x)))} will return “A”,”E”,”I”
consonants($x)
This command returns a list of consonants in a word.
{consonants(sort(unique($x)))} will return “C”,”H”,”M”,”S”,”T”
NOTE: The letter Y is not returned by either the vowels command or the consonants command.